
Machine Learning (ML) has transitioned from a research novelty from its beginnings in 1952 to an applied business solution with wide interest and enthusiasm from industry and academia alike in its implementation and adoption. As the field matured, it has become imperative to improve ML operation processes. This blog explores how small teams and organizations alike can use MLOps to productionize and successfully deploy their models to derive business value and ROI from their investments.
What is MLOps?
MLOps stands for Machine Learning Operations. It is a set of practices that combines DevOps, data engineering, and Machine Learning. MLOps aims to deploy and maintain ML models reliably and efficiently. Properly defined, MLOps is an engineering discipline, which seeks to unify ML systems development and deployment to streamline the delivery of machine learning models in production.

The MLOps Process
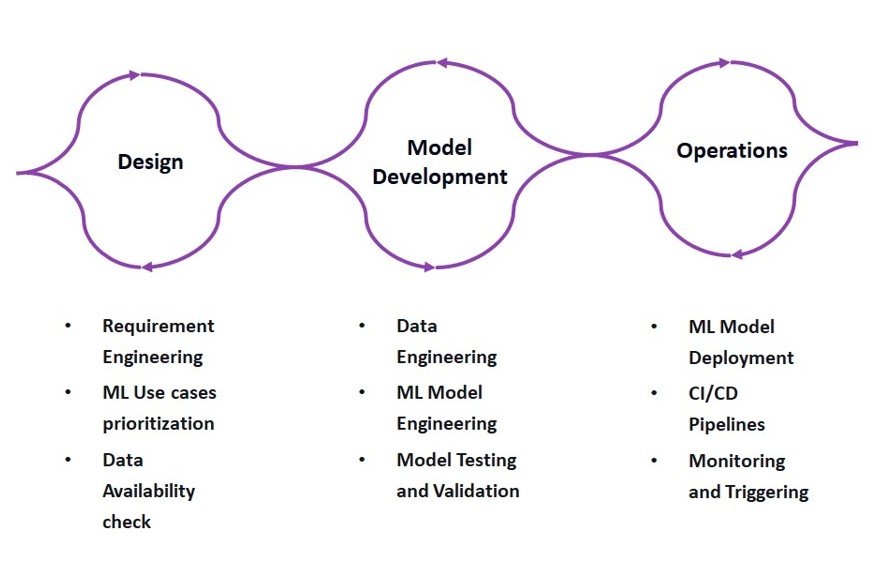
The complete MLOps process has three phases – Designing the ML powered application, ML experimentation and development, and ML operations. The first phase, simply called “Design”, involves identifying the potential users, broadly defining the ML solutions to solve the problem and assessing the further development of the project. This is devoted to business understanding, data understanding and designing the software. The next phase, “Model development” involves assessing the feasibility of ML for the problem by implementing a PoC to identify the suitable algorithm, polish the algorithm to refine the accuracy, and then arrive at a stable model, which delivers expected accuracy. This involves model engineering and data engineering. The next phase, “ML Operations” involves productionizing the stable model developed in the second phase by using established DevOps practices such as testing, version control, continuous delivery and monitoring. All the three phases influence and tie in at every stage of the MLOps process.
The Common Situation
Let’s assume a company has a team of data scientists and their demos of the model KPIs have overwhelmed their customers with their solutions that were intractable for many years. So naturally, the question arises, when can these models be put into production. If you are not familiar with MLOps, you might think this is easy. All that is left to do is routine IT work – you might think. Turns out you are wrong. According to Deeplearning.ai, only 22 percent of companies using ML have successfully deployed their models. This low number indicates the type of thinking prevalent in the other 78 percent of companies. To understand this situation, it is illustrative and helpful to look into its root cause.
The Root Cause
There is a fundamental difference between ML and software engineering. While software engineering is just code crafted in a carefully controlled environment, ML is more than that. ML is code plus data. The ML model (the entity put into production) is created by applying an algorithm on a mass of training data using code that will affect its behavior during production.
 More importantly, the model predictions depend on the incoming data during production and that’s something that cannot be known in advance. This is in contrast to software engineering where the output is completely deterministic. As they evolve, the code and data lines are two lines in different planes sharing only one dimension (time). This fundamental disconnect between the evolution of code and data causes several challenges which must be solved before putting a model into production.
More importantly, the model predictions depend on the incoming data during production and that’s something that cannot be known in advance. This is in contrast to software engineering where the output is completely deterministic. As they evolve, the code and data lines are two lines in different planes sharing only one dimension (time). This fundamental disconnect between the evolution of code and data causes several challenges which must be solved before putting a model into production.
Challenges of Productionizing ML Models
According to a survey by NewVantage Partners, of around 70 top enterprises, only 15 companies managed to successfully deploy AI features in their applications. Although, a substantial majority of them invested heavily in AI, this dismal percentage of success seems to point to an issue. The problem is that the unsuccessful companies faced several hurdles due to their manual process of deployment and production which are outlined here.
- Dataset dependency: Steps carried out during the training and evaluation stage in the development environment vary widely in the real-world scenarios. Data depends on the use case, which does not remain the same and changes in data fed to the model during retraining leads to poor accuracy in its predictions.
- Pipeline complexity: In the real world, models should be retrained on new data in order to maintain the relevance and regularity of their predictions with changing trends in business use cases. A common strategy would be to establish a pipeline between the model and a DataLake where the model has access to the latest data. Human approval is needed to match the models to the relevant features and data sources. This may work in case of a single model but imagine the case where there are ensemble models and their relevant pipelines and it gets worse with federated pipelines. According to a study by Gartner Inc, the number of models handled per company implementing AI and ML averaged globally is 20 in 2021.This number is expected to rise to 35 by 2022. This is the pipeline complexity problem with the manual process.
- Scalability issues: In a manual process of developing ML models, models are typically coded by a data scientist using tools like jupyter notebooks. Also, the focus is on getting the right algorithm and good accuracy using different frameworks like scikit-learn for python, caret for R etc. Each of these libraries and frameworks have their own limitations regarding scalability. The code written in such libraries does not scale in a production environment such as Hadoop where a different library such as pyspark for python and sparkR for R would be best suited.
- Monitoring limitations: The risk of ML models not performing well always exists and needs continuous monitoring and evaluation. Unlike in the development environment, incoming real-world data does not have parameters such as accuracy, precision, recall etc. Instead, methods such as data deviation detection, drift detection, canary pipelines, production A/B tests need to be used which can be served well by implementing an automated MLOps system.
- Process Limitations: Handling ML systems in production will require the skills of different branches of an organization each of which will have different skills and goals. Data scientists focus on accuracy and measure data deviation, business analysts will want to enhance KPIs and production operations engineers will want to see the uptime and resources. Production teams working individually cannot handle the complexity of the environment which has complex entities such as models, algorithms, objects, pipelines etc without working together. Also, there is a need to version control these entities together and keep track of the associated parameters and pipelines for each version of the model with time. This is the process challenge in the manual process without MLOps.
Need for MLOps
ML models which are not deployed are costly technical experiments at best but do not bring ROI. In the majority of companies, businesses don’t realize the full benefit of AI as models don’t make it to deployment. With manual and time-intensive processes, the timeline of the lifecycle is not in alignment with the speed and scale of the business. The models’ performance degrades due to randomness and entropy, thus being out of alignment with the original business need. Even if organizations identify model decay, manually updating models in production is a resource intensive and risky process with a high chance of outages. With MLOps, companies can deploy, monitor and update ML models efficiently, thus paving the way for AI with ROI.
MLOps- Compelling reasons to adopt
Adopting MLOps helps you get the most out of your data and capitalize on the data strategy, thus bringing about increased ROI and deriving deeper business value from ML operations and processes. Another reason for using MLOps is that it generates new revenue streams and improves customer experiences from the increased accuracy of ML models in production. Adopting an effective MLOps culture brings about standardized processes across model development, testing, deployment and management. It brings about centralization of data and with the introduction of feature stores, model versioning becomes a bit less complicated and easier. Also, it helps the ML models best fit the organization and increases reusability on cloud, on-premises and hybrid data storage and model deployment.
MLOps- The Benefits
Among many aspects of MLOps, the benefits directly relate to the organization’s ability to stay relevant and grow in the sphere of business. The benefits of MLOps are outlined here.
- Rapid innovation through robust ML lifecycle
- Create reproducible workflow and models
- Easy deployment of high precision models
- Effective management of the entire ML lifecycle
- Automated and efficient ML resource management system and control
From data processing to analysis and auditing – when all done correctly- MLOps is one of the most valuable practices an organization can have. MLOps can add a more valuable impact towards the growth of an enterprise, by improving quality and performance over time.
Conclusion
The benefits of MLOps are numerous and bring substantial increases in ROI for investments in ML projects. This is one of the most cutting-edge engineering disciplines that produces and transforms the business operations of any organization using it for their projects.
- Conversational AI to Transform Customer Interaction and Engagement - July 19, 2024
- AI-Enabled Financial Planning: Empowering Consumers for Better Decisions - February 27, 2024
- Revolutionizing Supply Chain Management with AI in Retail - January 8, 2024




Comments