
In a recent survey conducted by Deloitte on the Banking industry, 93% of the respondents indicated that fraud has grown in the last 2 years. Apart from the financial losses, these incidents leave a dent in the banks’ reputation.
These are 2 key sets of statistics that emerged from the survey.
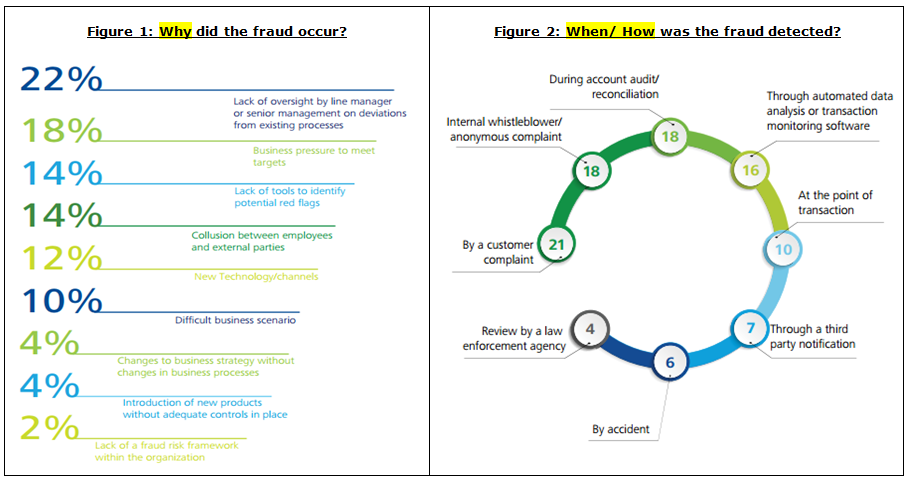
Let us examine Figure 1. Majority of the frauds happened due to either human negligence or malpractice. Part of the solution obviously is to train the staff better, tighten the manual processes, and increase the audits — in general, increase the sense of responsibility and ownership. But while those steps are definitely necessary, they are not sufficient. A large part of the solution is to use automated checks and balances throughout the workflow to ensure that such activities are either prevented before they occur, or at least caught and corrected at the time of occurrence.
With that background, let us look at Figure 2 now. Only about 26% were caught at the point of transaction (10%) or with an automated system (16%). Agreed that these statistics are based on a sample of the population and are approximate. But even after allowing for such a sampling error, it is clear that there is a huge opportunity for the banks to reduce their losses, both tangible as well as intangible. In fact, the intangible losses — loss of goodwill, loss of confidence/faith in the bank etc. — could lead to much deeper and long-term losses for the bank’s brand image and bottom line, especially in the wake of disruptive Fintech innovations knocking on the consumer’s doors.
So what’s the remedy?
Digital transformation
Banks should aggressively tap the architectural potential provided by Mobile, Cloud and Social, create pipelines for harnessing all that data into reservoirs, and then build a robust Analytics layer on top of that aggregated data, to aid in Data-Driven-Decisions. (Learn how Analytics are used to optimize Marketing ROI).
The initial Capital Expenditure and the marginal Operating Expenditure associated with this can easily be recovered by:
- Reducing routine/mundane manual checks, thereby allowing the management to utilize their human resources’ time for more intelligent work.
- Predicting fraud, thus aiding in its prevention.
- Quick detection and remediation just in case the fraud somehow slips under the radar during the prediction stage.
- Creating a defense mechanism against the threat posed by disruptive FinTech start-ups.
On the data so accumulated, the banks can perform various types of Analytics — Supervised and Unsupervised.
In Supervised learning, a set of Machine-learning algorithms are made to discern patterns in historical data, by studying how a set of attributes affect a target variable. For instance, how certain attributes like age, employment status, loan amount, tenure, purpose of loan etc. increase or decrease the probability of a person defaulting on his/her loan repayment. Once that set of patterns (called model) is created, it is just a matter of applying that on a new applicant to predict if s/he is likely to default on the loan payments. In fact, the model can give you the probability of default. Then, based on the business policy, the person can be denied/approved for the loan. (Check out the trends in big data that are affecting the banking and financial sector)
In short, Supervised learning predicts the value of a target variable based on historical relationships of this target variable with other attributes.
Unsupervised learning is a bit different. There’s no target variable. You do not know what you’re looking for upfront. The Data Scientist cuts loose an appropriate algorithm on a set of prepared data and investigates the results to unearth some anomaly, anything out of the ordinary. There are various algorithms — categorized as clustering, profiling, co-occurrence grouping etc. — available in the market.
Both the above techniques are being used in the industry for either predicting fraud before it happens, or, discovering it automatically after it happens.
Some more teeth can be added to fraud prediction by applying the prediction engine to a transaction as it happens, in real time. This is, unsurprisingly, called real-time or streaming analytics, and can become a very critical weapon in the bank’s fraud-defense repertoire. There are various solutions available in the market, and what works for you will be based on what your current technology infrastructure is and which specific business use cases are to be addressed, among other criteria.
Apart from fraud prediction/detection, there are other benefits to putting such an infrastructure in place. For instance, you would be able to identify patterns in loan application and use that wealth of information to segment your customers better, and use targeted marketing and churn prevention.
How does one go about setting up such an infrastructure?
While it would be tempting to go with a ‘big bang’ approach, and get into a large project for this purpose, it would not be advisable. The goal should be to execute this in an Agile manner with short value generation loops, governed by an overarching Enterprise Architecture roadmap. Identify one use case (or a closely related set of use cases), implement that, see some revenues being realized (or cost-savings) and then extrapolate that.




Comments