
Why Git?
Git is a distributed revision control system with an emphasis on speed, data integrity, and support for distributed work environment, non-linear workflows compared to the other VCS (Version Control Systems) in the market
How Git Supports Decentralised Workflow
Git can host multiple redundant repositories by design compared to the other VCS software based on centralized repository. This in turn supports fine grained branching mechanisms.
Every local machine where Git is adapted as VCS, there is a locally stored copy of entire source as Git is a distributed VCS. This makes access to file history extremely fast. Also repository access is easier even when the network connectivity is not available as every machine has the complete backup of the source stored locally. When there are many committers in the system and if any repository is lost due to system failure only the changes which were unique to that repository are lost. If users frequently push and fetch changes with each other this tends to be a small amount of loss, if any.
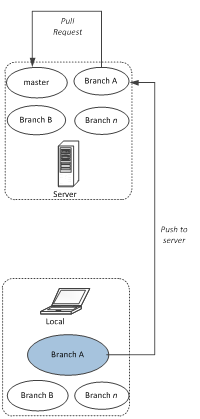
Here is a representation of how Git Vs SVN’s model works in terms of centralization of source access:
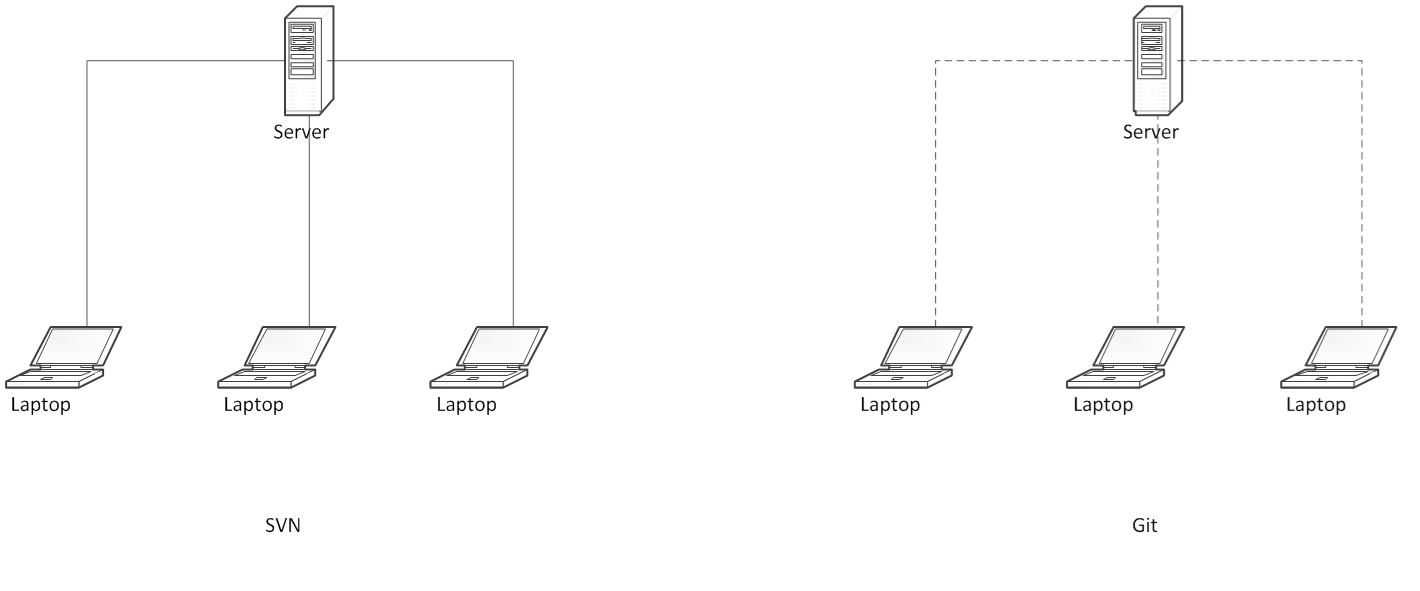 In a centralized VCS like Subversion (SVN) – as observed above – only the central repository has the complete history. This means that users must communicate over the network with the central repository to obtain history about a file. Backups must be maintained independently of the VCS. If the central repository is lost due to system failure it must be restored from backup and changes since that last backup are likely to be lost.
In a centralized VCS like Subversion (SVN) – as observed above – only the central repository has the complete history. This means that users must communicate over the network with the central repository to obtain history about a file. Backups must be maintained independently of the VCS. If the central repository is lost due to system failure it must be restored from backup and changes since that last backup are likely to be lost.
Git Best Practice: Use Git when you want to make sure developers are able to work on source changes even when there is no network connectivity and not worry about the other parallel teams working on the same source
Faster and Efficient Branching
When many different branches have to be maintained for many different features and also for multiple customers with distributed development teams, Git will serve as the best option to serve this scenario because of its efficient and quicker branching capability
Branching in Git is a very core concept such that every developer’s working directory is itself a branch. Even if two developers are modifying two different unrelated files at the same time it’s easy to view these two different working directories as different branches stemming from the same common base revision of the project.
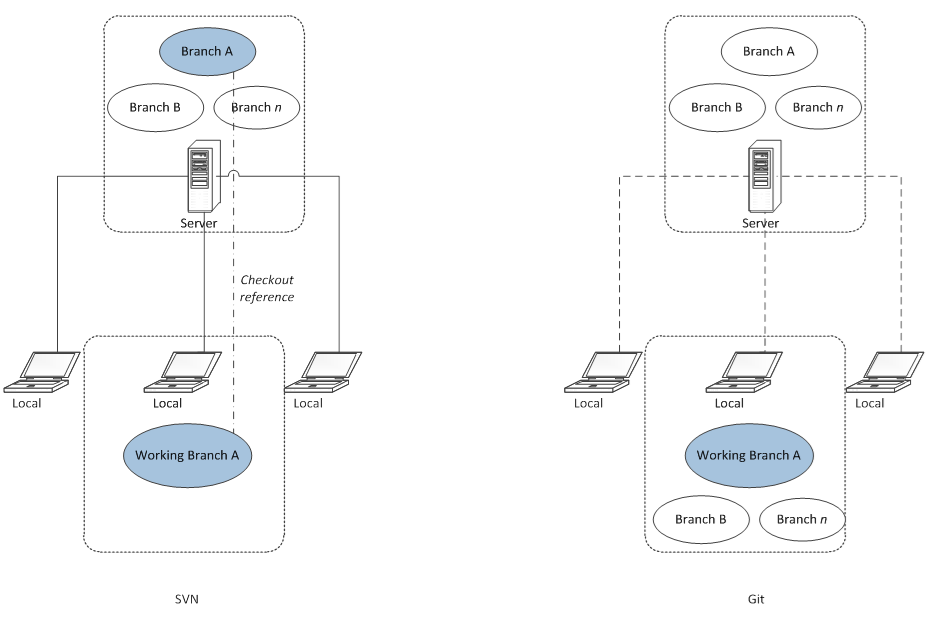 With a typical centralized-based VCS like SVN, the branches are stored mainly on the server. Whenever a developer wants to work on a branch, source from the branch has to be checked out first from server to local. During checkout, source for branch is fetched into local.
With a typical centralized-based VCS like SVN, the branches are stored mainly on the server. Whenever a developer wants to work on a branch, source from the branch has to be checked out first from server to local. During checkout, source for branch is fetched into local.
Git does away with centralization. First time a source is fetched from Git, it fetches all the branches to local and maintains a copy there. Since Git branches are light weight, they do not consume much disk space either. Whenever a developers “checks out” it is only treated as a switch to that particular branch so that source in that branch becomes active in local directory, replacing whatever was present from earlier branch. (Do not worry! Git warns when there are pending changes from previous branch and provides ways to back them up temporarily.)
The major advantage this provides is in code diff. Changes from the previous version of current branch (or with another branch altogether) can be compared to the working branch easily without requiring access to central repository.
Git Best Practice: Choose Git when you want to make sure you are able to work with multiple branches easily and do diff without access to central repository
Commiting Changes to the Git
Most of the times when a developer completes a change in a specific branch from a repository, it has to be submitted to review before committing those changes to the main branch which could be in the same repository or a different one. This is handled in different ways by different version control systems.
Git handles this mainly through “Pull Requests”. A pull request is a mechanism to ask another developer to merge changes from one branch in a repo to another branch in the same repo or another one. That target branch is called up-stream branch (i.e. in simple terms, branch from which the source was originally fetched.)
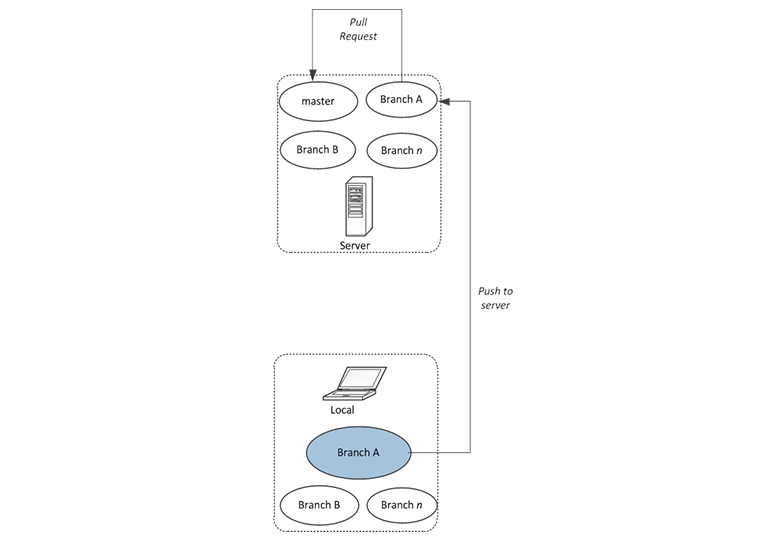
Git Best Practice: Use pull requests effectively to make sure changes are properly reviewed and pulled/merged into the main branch.
Handling Larger Source Repositories
Git works mainly based on local repositories and this attributes to its extremely fast nature. This comes in handy when the source repo is large and a developer is expected to work with multiple branches on a single source (e.g. multiple customers). Since all operations are local there is no network latency involved to:
- Perform a diff.
- Views file history.
- Commit changes.
- Merge branches.
- Obtain any other revision of a file (not just the prior committed revision).
- Switch branches.
Git Best Practice: When there are multiple customer bases to support with customizations, use Git branches to manage such customizations across customers.
Managing Shared Resources with Fork and Merge Model
Consider a large organization with world-wide presence and that uses organization-wide libraries or frameworks. In such a setup, managing changes is cumbersome. Capable developers would need access to repository, but the process of even identifying their capability through source change is never easy due to the scale of the organization.
Git helps in making this easier. With Git, a developer can usually fork a framework repository so that it is then copied as his own repository in a different base (e.g. in a particular division of the organization). Once the changes are completed, the developer could submit a pull request to the lead of the framework project, who could then review it and choose to merge the changes or reject them.
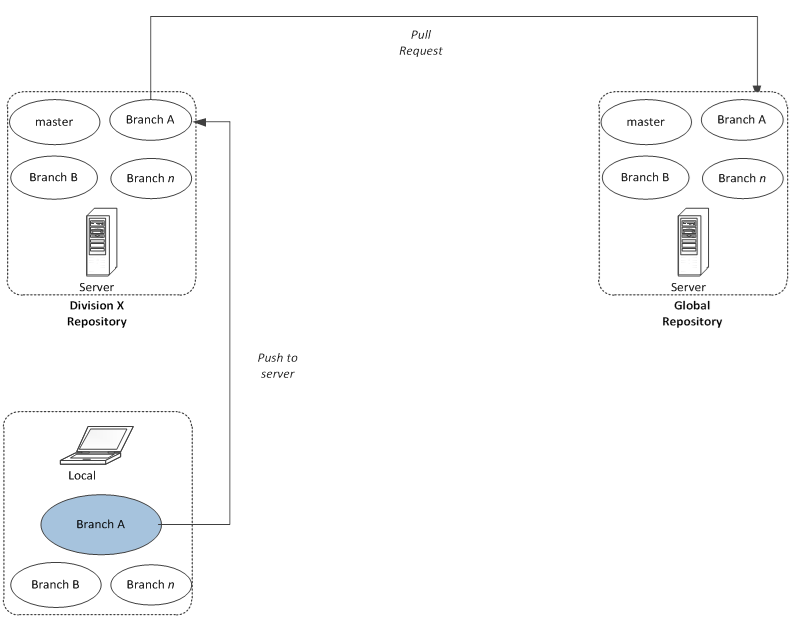
Git Best Practice: Use fork and merge model when you want to manage libraries / frameworks across organization at a larger scale.
Making Releases with Git
Releases are usually done from a release branch. Tags can be created while doing a release. A tag is a light weight mechanism to name a release e.g. 1.2.1.
Git has two types of tags – light-weight (default) and annotated (stores complete code). Since light-weight is the default option, it is much preferred by the developer community while using Git.

Git Best Practice: Always tag releases to enable going back a point in time of the release to make bug fixes.

- EFFECTIVELY USING GIT FOR DISTRIBUTED WORK ENVIRONMENT - August 7, 2015
- Webcast – How to Scale Continuous Delivery in the Cloud? - May 21, 2015
- Why testing setup will make or break your continuous deployment? - April 29, 2015




{kind=link}
{kind=link}
Comments